







Neural Networks: Transforming Image Processing in Businesses
By Umang Dayal
March 27, 2024
A regular image can easily be transformed into “Starry Night”, a painting style used by Vincent Van Gogh. This process is part of an image manipulation technique that uses deep learning algorithms to transform images.
This blog will explore how machines perceive images, the function of neural networks, and commonly used image-processing techniques.
What is Image Processing?
Image processing involves enhancing existing images. It deals with manipulating digital images using computer algorithms for applications such as object detection, image compression, or facial recognition technology.
Computer vision along with deep learning algorithms can dramatically improve the performance of such models.
How Computer See Images?
Digital image processing deals with 2D or 3D matrices, where pixel values represent dimensions, known as intensity or pixels. The computer sees digital images as a function of I(x,y) where “I” denotes the intensity of the pixel and (x,y) represents coordinates binary, grayscale, or RGB images.
Computer image processing consists of various image-based functions such as.
1. Binary Image
Images with pixel intensity “0” represent black, and “1” represent white in binary images. Such an image processing method is generally used for highlighting colored parts of an image and also used for image segmentation.
2. Grayscale Image
Grayscale comprises 256 unique colors where pixel intensity of “0” denotes a black color and 255 represents a white color. All colors between 0 to 254 represent different shades of gray color.
3. RGB Color Image
The most commonly used images are RGB or colored images consisting of 16-bit matrices. This means 65,536 unique colors can be represented for each pixel. RGB simply means Red, Green, and Blue color channels of an image.
When the pixel value is (0,0,0) it denotes black color and when it is (255, 255, 255) it signifies white color. Any other combination of these 3 numbers can denote different colors. You can see a few combinations of RGB colors below.
Red (255, 0, 0)
Green (0, 255, 0)
Blue (0, 0, 255)
4. RGBA Image
RGBA is similar to RGB with the addition of “A,” representing “Alpha,” which denotes the opacity range of the image from 0 to 100%.
Utilization of Neural Networks in Image Processing
Neural networks are revolutionizing the computer vision industry by allowing machine learning to analyze and understand images. Convolutional neural networks (CNN) have become one of the most popular techniques of image processing, where neural networks employ various methods to process images, recognizing them for training data or generating accurate results.
Some of the most common neural network image processing techniques include:
Image Classification: It signifies assigning a label based on the category of the image, whether it is an image of a cat, fish, or a dog.
Object Detection: This technique identifies different objects inside an image.
Image Segmentation: This converts an image into various regions of pixels that can be represented in a labeled image by masks.
Image Generation: The most commonly used computer vision technique where new images are generated based on certain criteria.
There are various other neural networks used in image processing such as landmark detection, image restoration, human post estimation, style transfer, etc.
Learn more: 5 Best Practices To Speed Up Your AI Projects
Most Common Image Processing Techniques
Image Enhancement
Image enhancement improves the quality of an existing image. It is widely used in remote sensing and surveillance systems. Image enhancement can be used to adjust the contrast and brightness of an image. Both brightness and contrast can be adjusted by multiple image editing applications making it lighter and clearer to see. The below image displays how image enhancement works; (a) is the original image used in the process.

Source: Study
Image Restoration
This image processing technique can be used to restore the quality of damaged or unclear images. This method is often used to potentially restore historically damaged documents or images. The image below shows how the image restoration process works.

Source: Guvi
Deep learning algorithms in computer vision can help reveal a lot of information from torn documents. An image restoration technique called image inpainting fills in missing information using pixels in the image. This is done using synthesis image algorithms to fill in missing information using pattern recognition techniques.
Read more: Everything You Need To Know About Computer Vision
Image Segmentation
Image segmentation is a computer vision technique to partition images into different regions or segments. Each segment in the image denotes a unique object which is mostly used in training data for object detection. The below image shows how image segmentation is used in the medical industry.

Source: Paper
Binary thresholding is the most common approach in image segmentation. It's a process where each pixel is either denoted by the color black or white. A threshold value is chosen at the start and any pixel that goes above the threshold level is turned white and pixels that go below the threshold limit are turned black. This method segments images distinctly using black-and-white pixel regions.
In medical imaging such as MRI segmentation multi thresholding technique is used where different image parts are converted into unique shades of grey color. An example of MRI image segmentation is shown below.
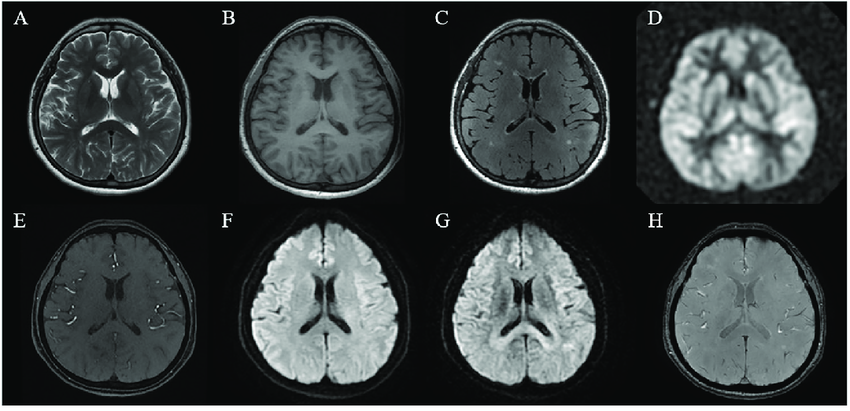
Source: Paper
Object Detection
Object Detection is a method of identifying objects in an image using deep learning models. These neural networks detect objects using a bounding box which signifies the object with its class label. Convolution Neural Network (CNN) is designed for image processing to see patches in an image instead of dealing with a single pixel at a time. The image below displayed a use case for CNN in remote sensing.

Source: Paper
Computer vision algorithms identify an object's location in the image by creating a box around it. These inputs are analyzed to determine the object's location by considering its height, width, and the position of the bounding box.
The most commonly used neural networks in object detection are:
R-CNN and Faster R-CNN
You Only Look Once (YOLO)
Single Shot Detector
Retina-Net
Read more: The Impact of Computer Vision on E-commerce Customer Experience
Image Generation
Neural networks are developed to understand large datasets of images and generate realistic images, a process also known as Image Generation. A complex process that generates new images based on the data set of input images. Several neural network architectures have been developed for image generation, including Variational Autoencoders (VAEs), Autoregressive Models, and Generative Adversarial Networks (GANs). Besides these architectures, there are a few hybrid solutions created by OpenAI such as DALL-E.
GAN includes two separate models; generator and discriminator. The Generator creates synthetic images that look realistic and try to fool the discriminator, while the discriminator acts as a critique to identify whether the image is real or synthetic. The image below explains the generic workflow of the Generative Adversarial Network.

Source: Paper
These two models work simultaneously through multiple iterations to produce high-quality photo-realistic images.
Final Thoughts
We have discussed a brief overview of how neural networks transform image processing. Each neural network has its own architecture and functionality in image processing to perform specific tasks. A lot of effort and image processing algorithms such as CNN work coherently to simplify business processes in computer vision.
We at DDD offer image processing services based on neural networks.