





Read our latest blogs and case studies
Deep dive into the latest technologies and methodologies that are shaping the future of Generative AI

We offer expertise for the entire life cycle of autonomous systems, from development, operational support to go to market solutions. Learn More

Providing multimodal labeling, annotation, and testing solutions for autonomous systems, geospatial data, GenAI model evaluation, and red teaming in defense, federal, and public sectors. Learn More

We offer data preparation solutions to drive efficiency andinnovation on the modern farm. Learn More

Partnering with AgTech companies and food producers to create clean AI/ML datasets that drive innovation in food supply solutions, precision agriculture, farm automation, and smart resource management. Learn More

Leveraging computer vision and natural language processing solutions to drive innovation across diverse industries worldwide. Learn More

We support mission-critical outcomes with precision, scalability, and security by integrating data, automation, and US-based human-in-the-loop systems. Learn More
We offer expertise for the entire life cycle of autonomous systems, from development, operational support to go to market solutions. Learn More
We support mission-critical outcomes with precision, scalability, and security by integrating data, automation, and US-based human-in-the-loop systems. Learn More
Providing multimodal labeling, annotation, and testing solutions for autonomous systems, geospatial data, GenAI model evaluation, and red teaming in defense, federal, and public sectors. Learn More
We offer data preparation solutions to drive efficiency andinnovation on the modern farm. Learn More
Partnering with AgTech companies and food producers to create clean AI/ML datasets that drive innovation in food supply solutions, precision agriculture, farm automation, and smart resource management. Learn More
Leveraging computer vision and natural language processing solutions to drive innovation across diverse industries worldwide. Learn More

Sign up with your email address to download the eBook and the latest updates.

Safety Critical Events Identified, Analyzed, and Reported at a Market Leading P95 Quality Rating
Safety Critical Events Identified, Analyzed, and Reported at a Market Leading P95 Quality Rating
Pilot Projects Converted to a Full-Scale Production Pipeline
Pilot Projects Converted to a Full-Scale Production Pipeline
Top of the Line Cost Savings for ML Data Operation Customers
Top of the Line Cost Savings for ML Data Operation Customers
Time to launch a new Data Operations Workstream from ground-up, concept to delivery
Time to launch a new Data Operations Workstream from ground-up, concept to delivery

At Digital Divide Data (DDD), we place high-quality data at the core of the Gen AI development lifecycle.
We ensure your models are trained, fine-tuned, and evaluated using relevant, diverse, and well-annotated datasets. From data collection and labeling to performance analysis and continuous feedback integration, our approach enables more accurate, personalized, and safer AI outputs.
Our holistic approach and excellence in understanding Gen AI development are reflected in our use-case offering. Select one or more of these solutions to learn more about our technical competencies for Gen AI solutions.

Training LLMs (Large Language Models): Collect large volumes of text to teach AI to generate human-like writing, answer questions, summarize, etc.

Training Image Generation Models: Gather labeled images to enable AI to create original artworks, realistic photos, and design prototypes.

Training Voice and Speech Models: Collect high-quality audio for AI to generate or mimic human voices, accents, and languages.

Video Content Generation:Build video datasets for AI models that create synthetic videos or animate still images.

Multimodal AI Training: Collect datasets that combine text, image, video, and audio for models like OpenAI’s Sora or Gemini 1.5.

Synthetic Data Creation: Generate fake but realistic data to expand training sets without additional real-world collection costs.

Personalization Training: Collect user-specific interactions to help GenAI systems create personalized outputs (e.g., personalized ads, chatbots).

Localization and Multilingual Models: Collect data across languages and cultures to train GenAI models that can work globally.

Text Annotations: Label sentences, entities (names, places, products), topics, and sentiments to train LLMs and chatbots.
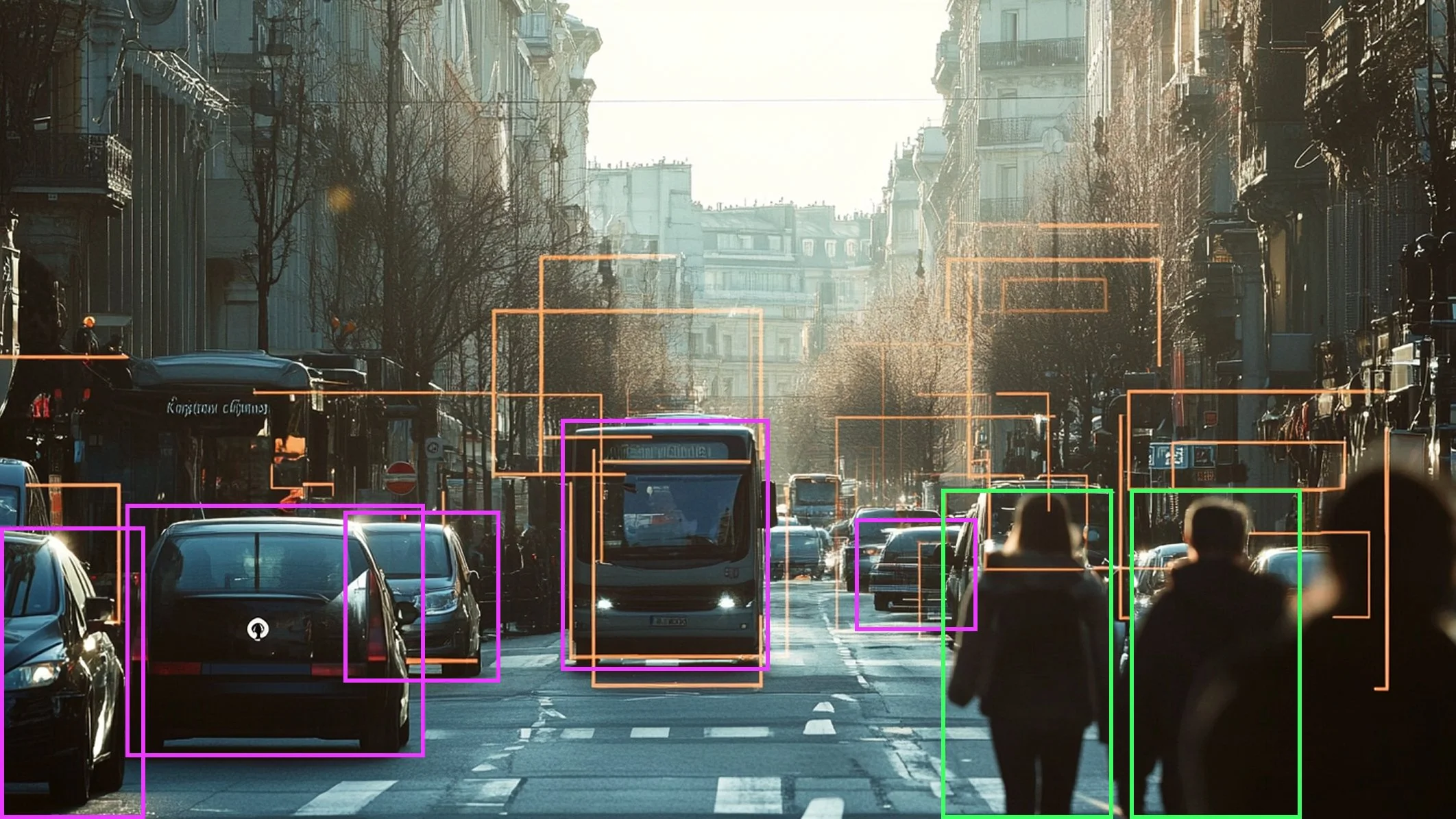
Image Annotation: Tag objects, classify images, mark bounding boxes or segment areas to train text-to-image and image generation models.
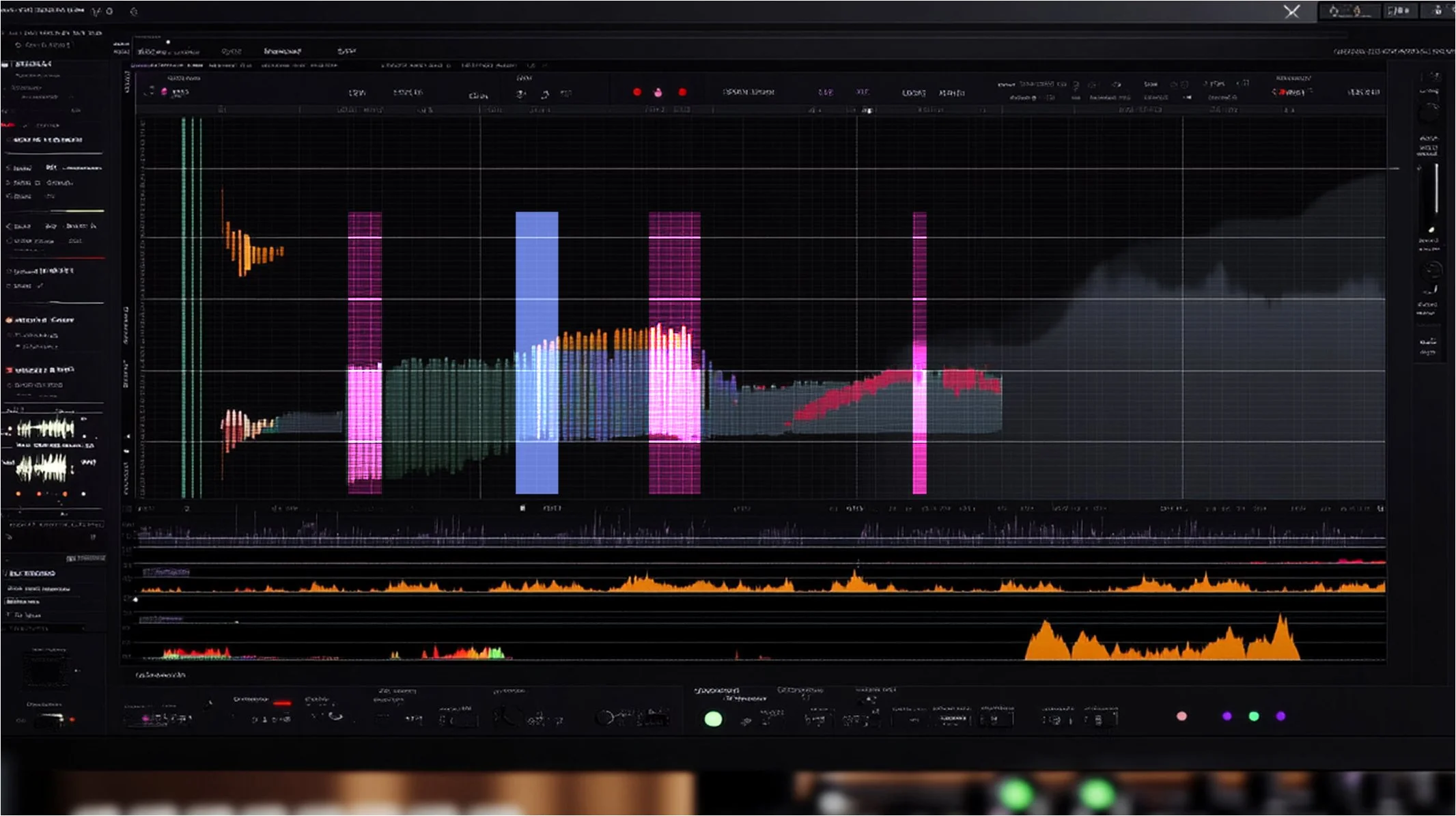
Audio Annotation: Label speech data (e.g., speaker identity, emotions, transcriptions) to train voice assistants and voice synthesis models.
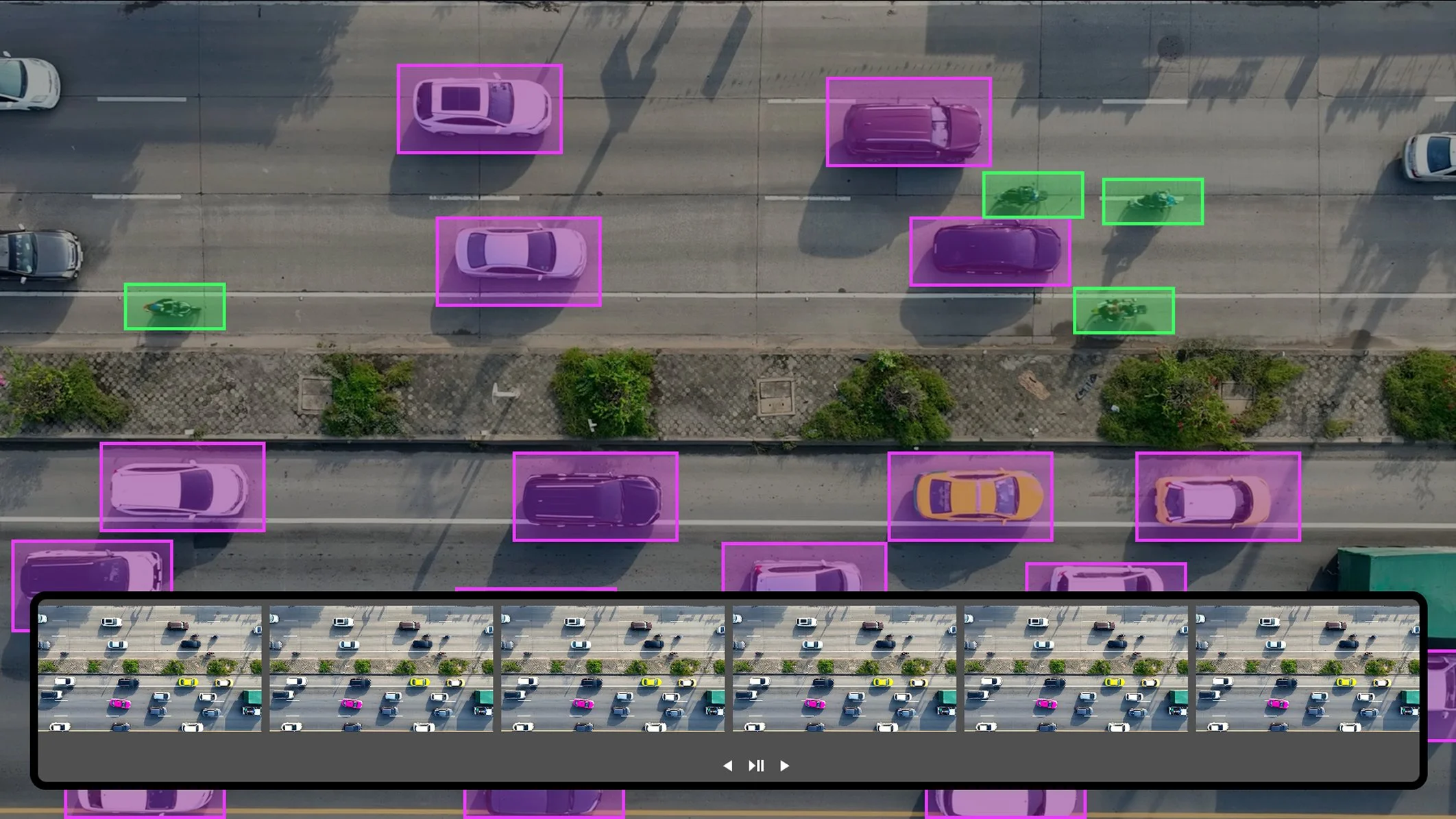
Video Annotation: Identify and label activities, objects, or frames to train video generation and multimodal models.

Multimodal Annotation: Link text descriptions to images, videos, or audio to enable models like Gemini or GPT-4o to handle mixed data types.

Synthetic Data Labeling: Annotate AI-generated data (text, image, or audio) for quality control and further model fine-tuning.

Bias, Toxicity, and Safety Annotation: Tag harmful, biased, or unsafe outputs to train models on ethical, inclusive content generation.

Domain Specialization: Tailor a general GenAI model (like GPT or Gemini) to perform better in specific industries like healthcare, legal, finance, retail, etc.

Task-Specific Optimization: Fine-tune a model for a focused task like summarization, translation, customer support, code generation, etc.

Instruction Following Improvement: Train models to better understand and execute complex or nuanced instructions.

Bias and Safety Alignment: Fine-tune models to reduce harmful, toxic, or biased outputs (ethical model alignment).

Multilingual Expansion: Fine-tune models on specific languages or regional dialects to support global communication.

Reduced Hallucinations: Fine-tune with factual, verified datasets to minimize generation of false information.

User Preference Alignment: Fine-tune based on user behavior, feedback, and preferences to make interactions feel more personalized.

Accuracy Testing: Measure how correct the model’s outputs are compared to ground truth (e.g., correct answers, facts, logical reasoning).

Factual Consistency Evaluation: Test whether the model generates factually accurate information and reduces hallucinations.

Bias and Fairness Assessment: Check if the model's outputs show bias based on gender, race, culture, geography, etc.

Toxicity and Safety Testing: Evaluate if the model produces harmful, offensive, or dangerous content.

Multilingual and Localization Testing: Test model performance across different languages, dialects, and cultural contexts.

Response Relevance and Context Awareness: Evaluate whether the model’s answers stay on-topic, logical, and appropriate to the conversation or input.

Task-Specific Evaluation: Measure model performance on specialized tasks like code generation, summarization, translation, image captioning, etc.
User Preference and Satisfaction Testing: Collect human feedback (e.g., ranking outputs) to see if users find the model’s responses helpful and high quality.

Safety Testing: Probe the model with adversarial prompts to see if it generates harmful, toxic, or violent content.

Bias Detection: Test model outputs across sensitive topics (race, gender, religion, politics) to uncover biases.

Misinformation & Hallucination Checks: Challenge the model with misleading or trick questions to evaluate its factual accuracy.

Security Exploit Testing: Try to prompt the model to reveal hidden instructions, internal data, or unauthorized actions (e.g., jailbreaks).

Prompt Injection Defense: Simulate prompt attacks to test if the model can be manipulated via user inputs in chat or API calls.

Content Moderation Stress Testing: Push the model toward NSFW or policy-violating outputs to evaluate filter and moderation robustness.

Instruction Misuse Scenarios: Try to misuse the model for banned tasks (e.g., making weapons, writing malware, phishing tactics).

Compliance Verification: Test model behavior against legal, ethical, or company-specific AI compliance frameworks.

Multimodal Red Teaming: Evaluate risks in image, video, or voice generation (e.g., deepfakes, visual misinformation, fake voices).

Child Safety Testing: Ensure GenAI cannot be used to create, promote, or describe harmful content involving minors.

Enterprise Knowledge Assistants: Answer employee questions using internal documents, wikis, reports, and SOPs, reducing time spent searching for information.

Customer Support Automation: AI chatbots retrieve relevant troubleshooting steps, FAQs, or manuals to resolve customer issues with precision and consistency.

Healthcare & Clinical Decision Support: Assist clinicians by pulling insights from medical literature, patient histories, or treatment guidelines to aid decision-making.

Legal & Compliance Research: Support legal teams by retrieving and summarizing contracts, policies, case law, and regulatory materials to improve research efficiency.

Education & Research Tools: Summarize academic papers, extract facts from textbooks, or answer research questions by leveraging digital libraries and databases.

E-commerce & Product Assistants: Help customers discover and compare products by retrieving specs, reviews, guides, or compatibility info from product catalogs and forums.

Developer Support & Documentation: Answer coding queries by pulling relevant code snippets, libraries, or tutorials from public docs, internal wikis, or Stack Overflow-like sources.

Conversational AI Assistants: Improve chatbot responses' tone, empathy, and clarity, ensuring outputs are polite, engaging, and appropriately informative.

Content Moderation & Safety: Reduce generation of unsafe, biased, or offensive content by reinforcing safety-aligned behaviors based on human ratings and edge case analysis.

Creative Content Generation: Refine writing style, coherence, and originality by training models to match user preferences in tone, genre, or storytelling structure.

Code Generation & Developer Tools: Enhance the quality and readability of AI-generated code by learning from human corrections, reviews, and style guidelines.
Personalized Learning & Tutoring Systems: Adapt explanations and content difficulty based on learners’ feedback, enabling AI tutors to support different skill levels and learning speeds.
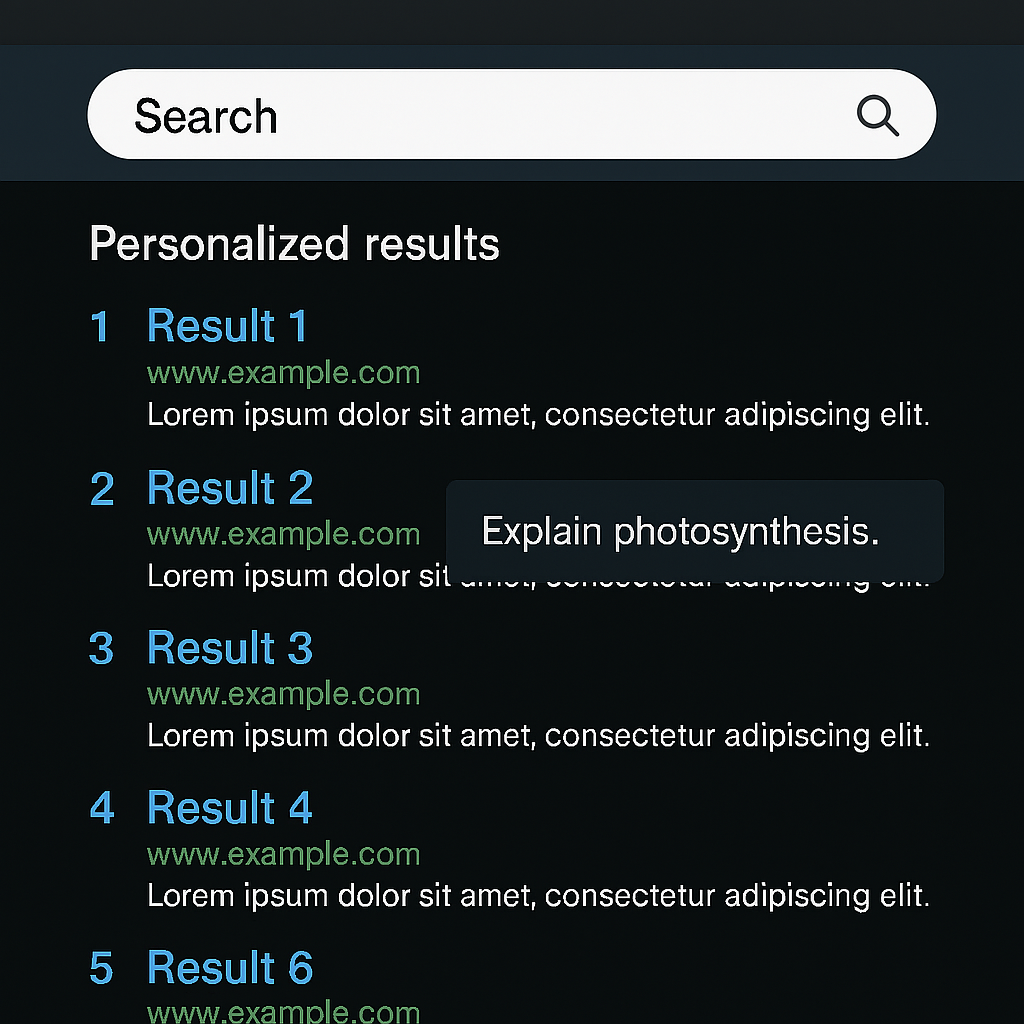
Search Ranking and Recommendations: Optimize search engines and recommender systems by rewarding content that users find more accurate, relevant, or satisfying.

Enterprise Task Assistants: Improve how AI handles workflows, multi-step instructions, or structured business tasks by reinforcing patterns from expert users’ feedback.
Our Holistic approach and excellence for digital trust...

User Verification & ID Checks
Strengthen trust and security with advanced document verification, fraud flagging, and compliance checks to ensure every user is authentic and meets platform standards.

Spam & Bot Detection
Identifying fake accounts, automated bots, and suspicious posting patterns that disrupt user experiences and damage credibility.

Brand Safety & Ad Quality Review
Review ads and placements to guarantee alignment with brand rules, audience expectations, and industry standards.

We are more than a data labeling service. We bring industry-tested SMEs, provide training data strategy, and understand the data security and training requirements needed to deliver better client outcomes.
Our global workforce allows us to deliver high-quality work, 365 days a year, with data labelers across multiple countries and time zones. With 24/7 coverage, we are agile in responding to changing project needs.

We are lifetime project partners. Your assigned team will stay with you - no rotation. And as your team becomes experts over time, they train more labelers. That's how we achieve scale.

We are platform agnostic. We don't force you to use our tools, we integrate with the technology stack that works best for your project.

Deep dive into the latest technologies and methodologies that are shaping the future of Generative AI
DDD pioneered the impact sourcing model of offering employment to people from underserved communities. This socially responsible approach provides these individuals with a path to economic self-sufficiency.
Discover MoreGenerative AI services involve building, training, fine-tuning, and evaluating models that can produce human-like content, from text and images to voice, video, and code. These services are essential for creating smarter digital assistants, content automation tools, and enterprise copilots across industries such as healthcare, legal, education, and e-commerce. At DDD, we power these services with high-quality datasets, ethical oversight, and scalable infrastructure.
Our approach centers on data excellence, ethical oversight, and platform flexibility. We bring:
500M+ data points labeled with P95 quality.
SME-driven domain expertise.
Support for LLMs, multimodal models, RAG pipelines, and RLHF.
91% pilot-to-production success rate.
We help clients build safe, scalable, and high-performance AI solutions, from concept to deployment.
Red Teaming is a proactive technique to stress-test Gen AI models for vulnerabilities by simulating adversarial or unsafe scenarios. Our Red Teaming Services include:
Toxicity, bias, and hallucination testing.
Security exploit simulations (e.g., jailbreak attempts).
Prompt injection defense.
Compliance verification and multimodal risk evaluation.
This ensures your model meets the highest standards of safety, ethics, and regulatory compliance before deployment.
RAG combines LLMs with a retrieval system to enhance factual accuracy by grounding responses in external knowledge. We support:
RAG pipeline setup for domains like legal, healthcare, and customer support.
RAG fine-tuning with verified, structured data to reduce hallucinations.
Multilingual and domain-specific tuning to improve precision.
Whether you're building enterprise knowledge assistants or research copilots, we ensure your RAG systems are trustworthy and scalable.
Yes. Our fine-tuning services include:
Domain specialization (e.g., finance, healthcare, legal).
Task optimization (e.g., summarization, translation, code generation).
Bias/safety alignment and hallucination reduction.
Multilingual and personalization training.
We also annotate synthetic data and user feedback for continuous model improvement.
Absolutely. RLHF is a method where human judgments guide a model’s behavior through reinforcement learning. At DDD, we:
Collect and rank human feedback across use cases (e.g., tone, factuality, empathy).
Power RLHF pipelines with expert-labeled data and user preference scoring.
Apply RLHF for chatbots, content creation, safety alignment, and personalized tutoring systems.
This ensures models align more closely with human expectations and values.
Yes. We collect, annotate, and evaluate text, image, video, and audio data for training multimodal models. We also:
Generate and label synthetic data for model training and augmentation.
Support multimodal red teaming for visual misinformation and deepfake detection.
Our capabilities cover models like GPT-4o, Gemini, and Sora.



